TileFusion operates on four core concepts: Tile, Layout, TileIterator, and Loader/Storer, which facilitate the transfer of tiles between memory hierarchies.
Types
Core types in TileFusion are defined in the types directory.
Tile
A tile is a 1D (vector) or 2D (matrix) array that resides within one of the three GPU memory hierarchies. A tile is typically characterized by three attributes:
- Shape: The dimensions of the tile, specified by the number of elements along each axis.
- Layout: Layout is a parameterized function that maps a tuple of integer coordinates (representing the elements in the tile) to an integer. The lexicographical order of these coordinates can determine the sequence of elements within the tile.
- ElementType: The data type of the elements stored in the tile.
Based on the memory hierarchy where a tile resides, there are three different variants: GlobalTile, SharedTile, and RegTile.
Global Memory Tile
A 2D tile in global memory with a shape of $[64, 64]$, a RowMajor layout, and a float element type can be defined as follows:
using Global = GlobalTile<float, RowMajor<64, 64>>;
Shared Memory Tile
To define an equivalent tile located in shared memory:
// `is_swizzled = true` indicates the tile is swizzled in shared memory,
// which is a common practice to enhance shared memory access performance.
// The default value is false, which simplifies debugging.
using Shared = SharedTile<float, RowMajor<64, 64>, is_swizzled=true>;
Note: Both Global and Shared memory tiles use a RowMajor layout, although their physical memory layouts differ. This difference will be explained in the next section, Tiled Matrix Layout. Users don't need to concern themselves with these details. They only need to know that a shared memory tile is a 2D array with dimensions $[64, 64]$ and a RowMajor layout. The tile primitive will manage the layout automatically.
Register File Tile
For tiles located in the register file, the definition differs slightly. In CUDA, registers are thread-local. Consequently, when the aforementioned tile is located in the register file, it is partitioned across threads in the CTA. Therefore, the register tile held by an individual thread is defined as follows:
using Reg = RegTile<BaseTileRowMajor<float>, RowMajor<4, 4>>;
We will further discuss the second parameter of RegTile in the next section: Register Tile Layout.
Tile Layout
The shape of a tile defines a high-dimensional space, with each coordinate in this space represented by an integer tuple. The layout of a tile is a function that maps this integer tuple to an integer, providing a comprehensive and logical description of data, threads, warps, and other resources.
Given that a GPU’s three memory hierarchies favor different access patterns, there are conceptually three types of layouts in TileFusion: Matrix Layout, Tiled Matrix Layout, and Register Tile Layout.
Note: These three layouts are inter-composable, but an important simplification we made is that arbitrary nested composability is not supported; composition can be performed only once. This will be explained in the examples below.
Matrix Layout
The matrix layout is defined by its shape and strides. This layout is utilized for global and shared memory tiles, as well as for specifying the numbering of threads or warps. It is declared as follows:
using Layout = MatrixLayout<64 /*Rows*/, 64 /*Columns*/,
64 /*Row Stride*/, 1 /*Column Stride*/>;
// layout is a callable function that maps a tuple of integers to an integer
Layout layout;
for (int i = 0; i < 64; ++i) {
for (int j = 0; j < 64; ++j) {
int idx = layout(i, j); // idx = i * row_stride + j * column_stride
}
}
This is equivalent to:
using Layout = RowMajor<64, 64>;
As illustrated in Figure 1, the default element order of the above matrix layout follows the conventional row-major format.
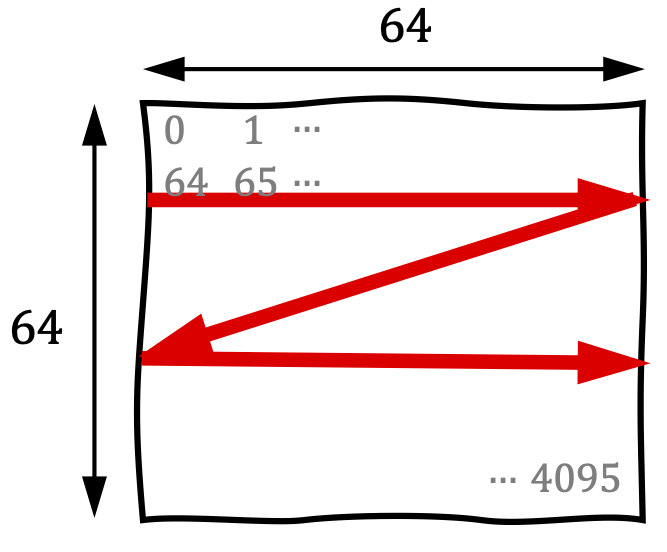
Figure 1: The row-major matrix layout.
Similarly, the column-major matrix layout is defined as:
using Layout = MatrixLayout<64 /*Rows*/, 64 /*Columns*/,
1 /*Row Stride*/, 64 /*Column Stride*/>;
This is equivalent to:
using Layout = ColMajor<64, 64>;
Row-major and column-major layouts are two specializations of the matrix layout.
Tiled Matrix Layout
The tiled matrix layout is specifically designed for the efficient access of shared memory tiles, and can be understood as a matrix layout composed with another matrix layout in concept.
A shared memory tile with a shape of [64, 64] and a RowMajor has a tiled matrix layout internally.
using Shared = SharedTile<float, RowMajor<64, 64>, is_swizzled=true>;
For the shared memory tile mentioned above, Figure 2 demonstrates how data is stored in the tiled matrix layout.
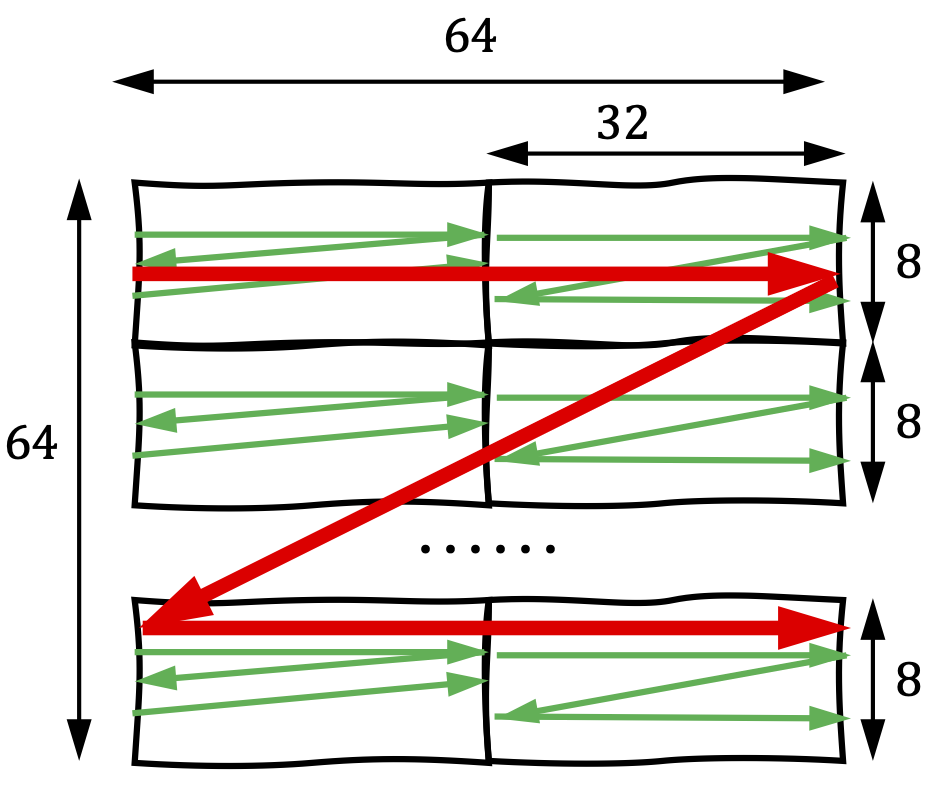
Figure 2: The tiled matrix layout used for the shared memory tile.
In a tiled matrix layout, the inner matrix is stored in a contiguous block of memory. The outer layout treats each inner matrix as a single element, arranging these elements into another matrix layout.
Specifically, let’s revisit the RowMajor<64, 64> for shared memory tile declared in the section Shared Memory Tile. It represents a matrix layout that is comprised of another matrix layout. For a detailed explanation of the rationale behind this approach, please refer to Tiles in Shared Memory.
Note: Specifically, let's revisit the RowMajor<64, 64> layout for the shared memory tile, as declared in the section Shared Memory Tile. This layout represents a matrix that is composed of another matrix layout. For a detailed explanation of the rationale behind this approach, please refer to Tiles in Shared Memory.
Register Tile Layout
The register tile layout is specifically designed to feed data to TensorCore. Conceptually similar to the tiled matrix layout, it is a depth-two nested array with a BaseTileMatrixLayout as the inner layout and a MatrixLayout as the outer layout.
Specifically, let’s revisit the register tile, as declared in the section Register File Tile. TensorCore’s MMA instruction has a hardware-prescribed tile shape and layout for the input operands. We prescribe a $[16, 16]$ basic building block to effectively leverage the MMA instruction. As shown on the left of Figure 3, a $16 \times 16$ basic tile feeding into the TensorCore is cooperatively held by a single warp. The first thread in the warp holds data in four segments, as indicated by the colors, and so on with the other threads in the warp. For a thread’s register tile, BaseTileRowMajor and BaseTileColumnMajor store these four segments in the single thread’s local register file.
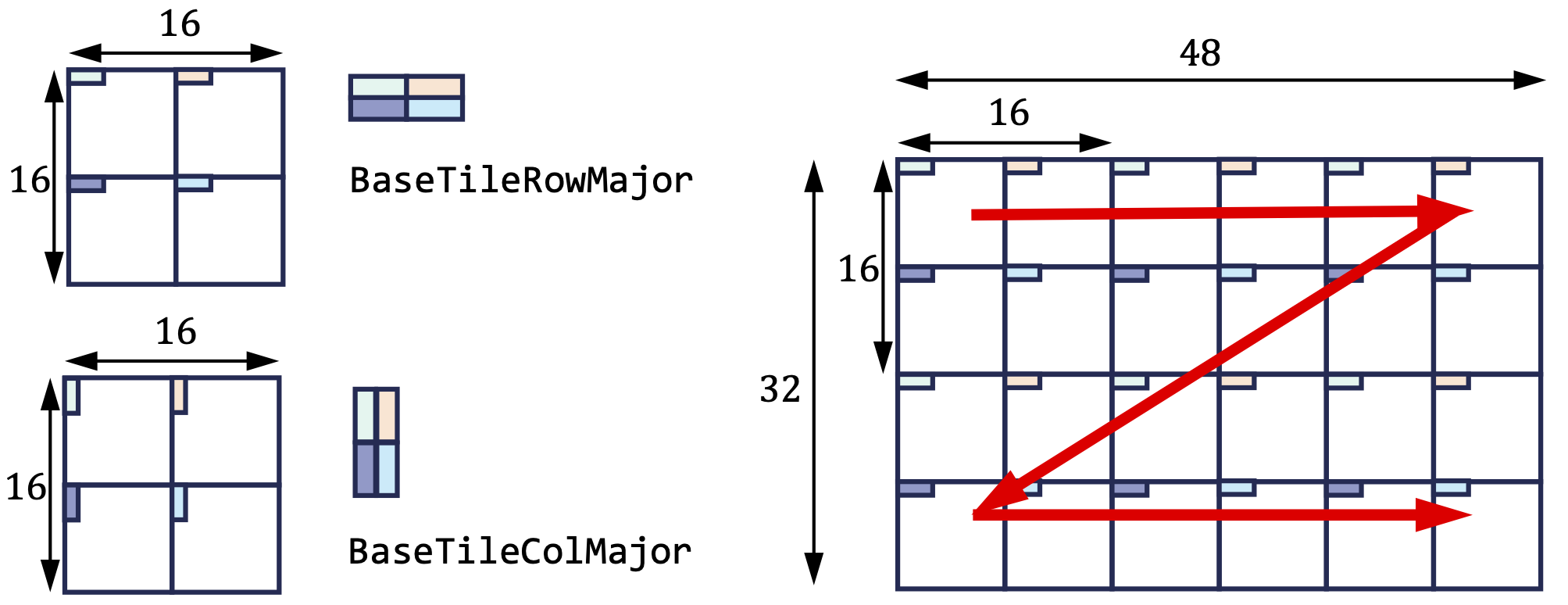
Figure 3: The TensorCore register tile layout.
Register layouts, based on BaseTileRowMajor and BaseTileColumnMajor, can be conceptualized as a depth-two nested array, with BaseTileMatrixLayout as the inner layout and MatrixLayout as the outer layout. The register tile depicted in the right part of Figure 3 is equivalent to the following definition:
using Reg = RegTile<BaseTileRowMajor<float>, RowMajor<2, 3>>;
Note:The interface for the register tile is coupled with the declaration of RegisterTile at the current version. The interface for specifying the register tile layout will be refined in the future to align more clearly with the underlying concept. For now, users can safely assume that implementations are guaranteed to follow the above description.
Tile Iterator
The tile iterator offers syntactic interfaces for defining tile partitions and facilitates tile traversal. Given that global and shared memory have distinct access patterns, there are two variants of tile iterators: GTileIterator and STileIterator. These iterators manage the differences in internal implementation. Despite these variations, both iterators maintain consistent behavior and interface:
// declare a global tile iterator
using Global = GlobalTile<float, RowMajor<kM, kN>>;
using GIterator= GTileIterator<Global, TileShape<kM, kTN>>;
// declare a shared tile iterator
using Shared = SharedTile<float, RowMajor<kM, kN>>;
using SIterator = STileIterator<Shared, TileShape<kM, kN>>;
As indicated by the code snippets above, the tile iterator accepts two arguments: the first being a tile and the second being the chunk shape. The chunk shape must be smaller than the tile shape. Essentially, the tile represents a larger data region, and the tile shape specifies the dimensions of a smaller tile. The tile iterator then divides the larger tile into smaller tiles along each dimension.
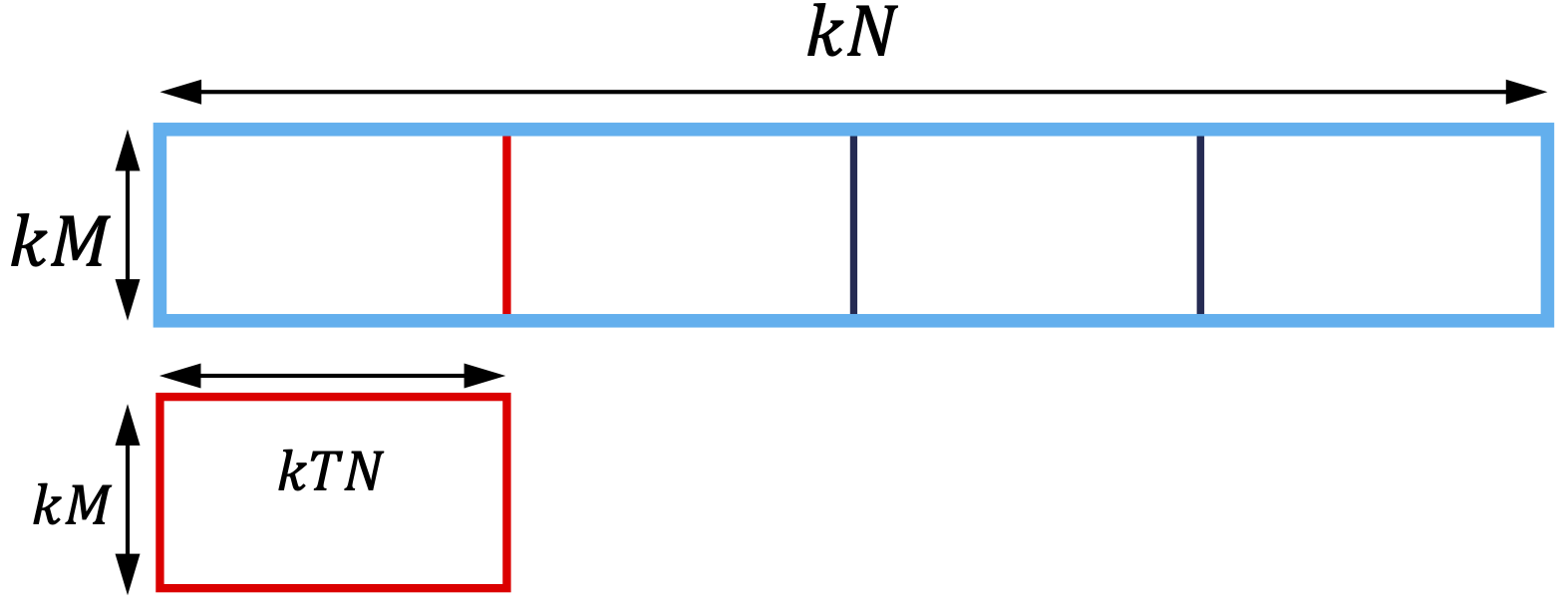
Figure 4: 1-D partition of a tensor using a tile iterator.
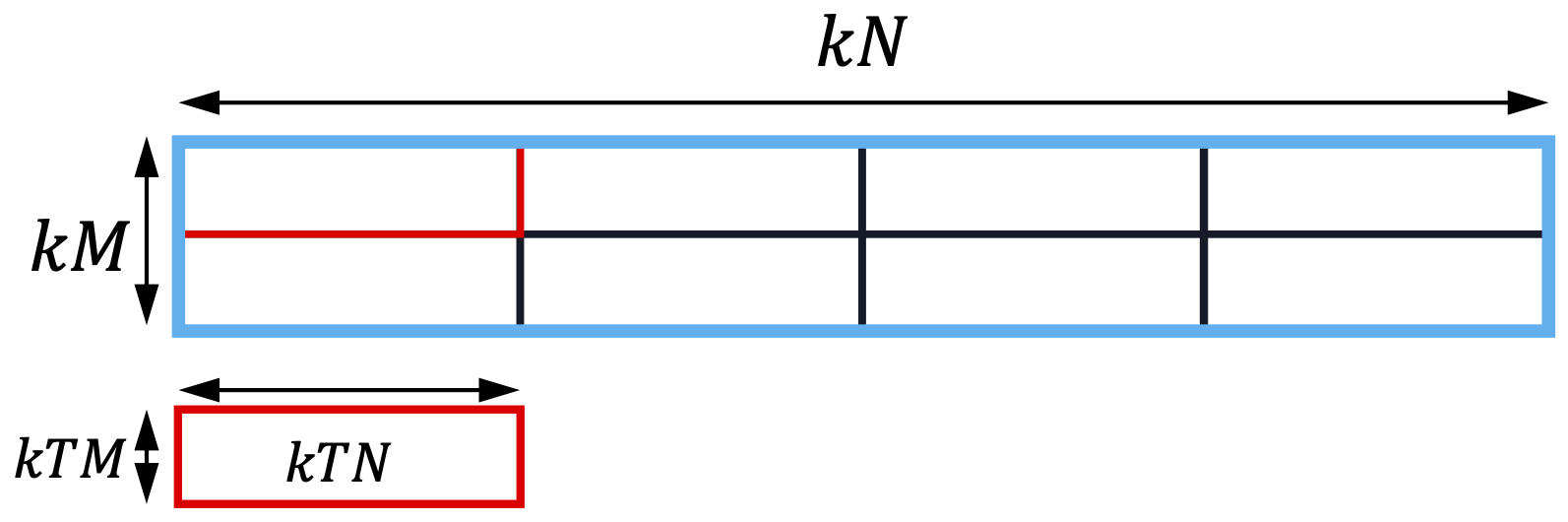
Figure 5: 2-D partition of a tensor using a tile iterator.
Since a tile in TileFusion is a 1D or 2D array, the tile iterator can partition a tensor into multiple tiles along one dimension (as shown in Figure 4) or two dimensions (as shown in Figure 5).
Loader and Storer for Tiles
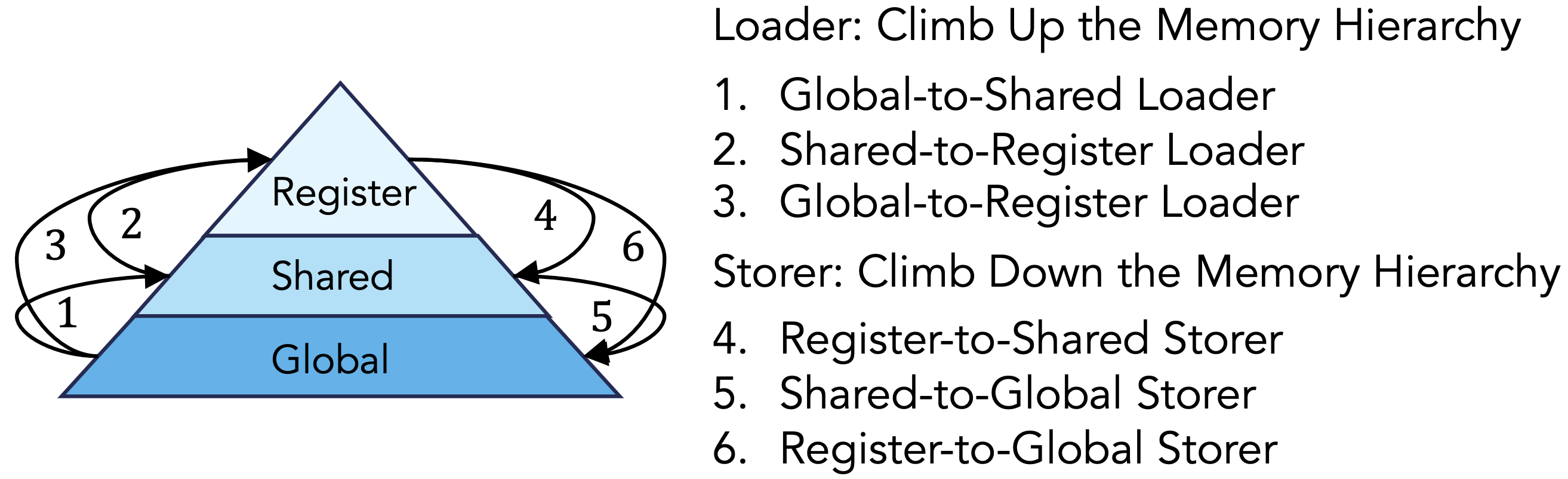
Figure 6: A tile is transferred between memory hierarchies using a loader and a storer.
Loaders and storers are found in the cell/copy directory. There are three types of loaders and three types of storers in total, as shown in Figure 6.
Loaders and storers operate at the CTA level and accept the following inputs: warp layout, target tile, and source tile. Based on these parameters, the internal implementation automatically infers a copy plan that partitions the data transfer work among the threads.
Example usages:
- For the usage of global-to-register loader and store, refer to the GEMM example in the examples directory, which leverages global and register memory without using shared memory.
- For the usage of global-to-shared and shared-to-register loader and store, refer to the GEMM example, which leverages all three levels of the GPU memory hierarchy.